

This is part 1 of a 2-part series on using pushdown automata for packet sequence validation. Read part two here.
As a software developer, most of my work day is spent working practically by coding and hacking away. Recently though I stumbled across an interesting problem which required another, more theoretical approach;
An OpenPGP message contains of a sequence of packets. There are signatures, encrypted data packets and their accompanying encrypted session keys, compressed data and literal data, the latter being the packet that in the end contains the plaintext body of the message.
Those packets can be sequential, e.g. a one-pass-signature followed by a literal data packet and then a signature, or nested, where for example an encrypted data packet contains a compressed data packet, in turn containing a literal data packet. A typical OpenPGP message can be visualized as follows:
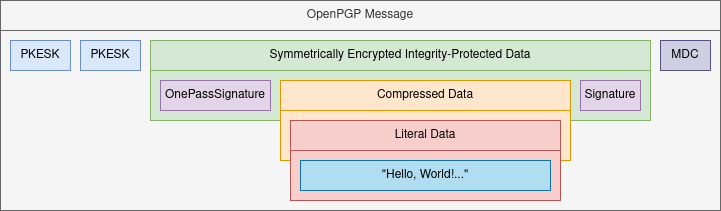
This particular message consists of a sequence of Public-Key Encrypted Session Keys (PKESKs), followed by a Symmetrically Encrypted Integrity-Protected Data packet (SEIPD), and Modification Detection Code packet (MDC). Decrypting the SEIPD using the session key obtained from any of the PKESKs by providing an OpenPGP secret key yields a new data stream consisting of a OnePassSignature (OPS) followed by a Compressed Data packet and a Signature. Decompressing the Compressed Data packet yields a Literal Data packet which in turn contains the plaintext of the message.
I am pretty confident that PGPainless can currently handle all possible combinations of packets just fine. Basically it simply reads the next packet, processes it in however way the packet needs to be processed and then reads the next packet. That makes it very powerful, but there is a catch! Not possible combinations are valid!
The RFC contains a section describing the syntax of OpenPGP messages using a set of expressions which form a context-free grammar:
11.3. OpenPGP Messages
An OpenPGP message is a packet or sequence of packets that corresponds to the following grammatical rules (comma represents sequential composition, and vertical bar separates alternatives):
OpenPGP Message :- Encrypted Message | Signed Message |
Compressed Message | Literal Message.
Compressed Message :- Compressed Data Packet.
Literal Message :- Literal Data Packet.
ESK :- Public-Key Encrypted Session Key Packet |
Symmetric-Key Encrypted Session Key Packet.
ESK Sequence :- ESK | ESK Sequence, ESK.
Encrypted Data :- Symmetrically Encrypted Data Packet |
Symmetrically Encrypted Integrity Protected Data Packet
Encrypted Message :- Encrypted Data | ESK Sequence, Encrypted Data.
One-Pass Signed Message :- One-Pass Signature Packet,
OpenPGP Message, Corresponding Signature Packet.
Signed Message :- Signature Packet, OpenPGP Message |
One-Pass Signed Message.
In addition, decrypting a Symmetrically Encrypted Data packet or a Symmetrically Encrypted Integrity Protected Data packet as well as decompressing a Compressed Data packet must yield a valid OpenPGP Message.Using this grammar, we can construct OpenPGP messages by starting with the term “OpenPGP Message” and iteratively replacing parts of it according to the rules until only final “Packet” terms are left.
Let’s create the message from the diagram above to illustrate the process:
OpenPGP Message
-> Encrypted Message
-> ESK Sequence, Encrypted Data
-> ESK, ESK Sequence, Encrypted Data
-> ESK, ESK, Encrypted Data
-> SKESK, ESK, Encrypted Data
-> SKESK, SKESK, Encrypted Data
-> SKESK, SKESK, SEIPD(OpenPGP Message)
-> SKESK, SKESK, SEIPD(Signed Message)
-> SKESK, SKESK, SEIPD(One-Pass Signed Message)
-> SKESK, SKESK, SEIPD(OPS, OpenPGP Message, Sig)
-> SKESK, SKESK, SEIPD(OPS, Compressed Message, Sig)
-> SKESK, SKESK, SEIPD(OPS, Compressed Packet(OpenPGP Message), Sig)
-> SKESK, SKESK, SEIPD(OPS, Compressed Packet(Literal Message), Sig)
-> SKESK, SKESK, SEIPD(OPS, Compressed Packet(Literal Packet("Hello, World!")), Sig)Here, cursive text marks the term that gets replaced in the next step. Bold text marks final OpenPGP packets which are not being replaced any further. Text inside of braces symbolizes nested data, which is the content of the packet before the braces. Some packet terms were abbreviated to make the text fit into individual lines.
Now, applying the rules in the “forwards direction” as we just did is rather simple and if no non-final terms are left, we end up with a valid OpenPGP message. There are infinitely many solutions for “valid” OpenPGP messages. A brief selection:
Literal Packet("Hello, World")
OPS, Literal Packet("Hey!"), Sig
OPS, OPS, Literal Packet("Hoh!"), Sig, Sig
SEIPD(Literal Packet("Wow"))
Sig, Compressed Packet(Literal Packet("Yay"))On the other hand, some examples for invalid OpenPGP packet streams:
<empty>
Literal Packet(_), Literal Packet(_)
OPS, Compressed Packet(<empty>), Sig
Literal Packet(_), Sig
OPS, Literal Packet(_)
SKESK, SEIPD(Literal Packet(_)), Literal Packet(_)Give it a try, I can guarantee you, you cannot create these messages using the OpenPGP grammar when starting with the term OpenPGP Message.
So now the problem becomes: How can we check, whether a given OpenPGP packet stream forms a valid OpenPGP message according to the grammar? Surely just trying to reverse engineer the message structure manually by brute force would be a daunting task… Luckily, theoretical computer science has a solution for us: Pushdown Automata!
Note: The following description of a PDA is kept brief and simplistic. I may well have made imprecise simplifications on the formal definition. If you want to learn more, but care about correctness, or if you are reading this post in preparation for an exam, you really should check out the Wikipedia page linked above instead.Me, perhaps not totally accurate on the internet
A Pushdown Automaton (PDA) consists of a set of states with transition rules between those states, as well as a stack. It further has an initial state, as well as a set of accepting states. Each time the automaton reads an input symbol from a word (in our case a packet from a packet stream), it pops the top most item from the stack and then checks, if there is a transition from its current state using the given input and stack item to another state. If there is, it transitions into that state, possibly pushing a new item onto the stack, according to the transition rule. If all input symbols have been read, the word (packet stream) is valid if and only if current state is an accepting state, the stack of the automaton is empty and there are no more input symbols left. If the current state is not accepting or if the stack of the automaton is not empty, the word is invalid.
Formally defined, a transition rule is a tuple (state, input-symbol, stack-symbol, state, stack-symbol), where the first state is the origin, the first stack-symbol is what needs to be popped from the stack, the second state is the destination and the second stack-symbol what we push back onto the stack.
There is a special symbol ‘ε’ which means “nothing”. If the input symbol is ε, it means we can apply the rule without reading any input. If a stack symbol is nothing it means we can apply the rule without popping or pushing the stack.
I translated the OpenPGP grammar into a PDA. There is an initial state “start”, a single accepting state “Valid” and a set of transition rules which I annotated with arrows in the following diagram. Let’s take a closer look.
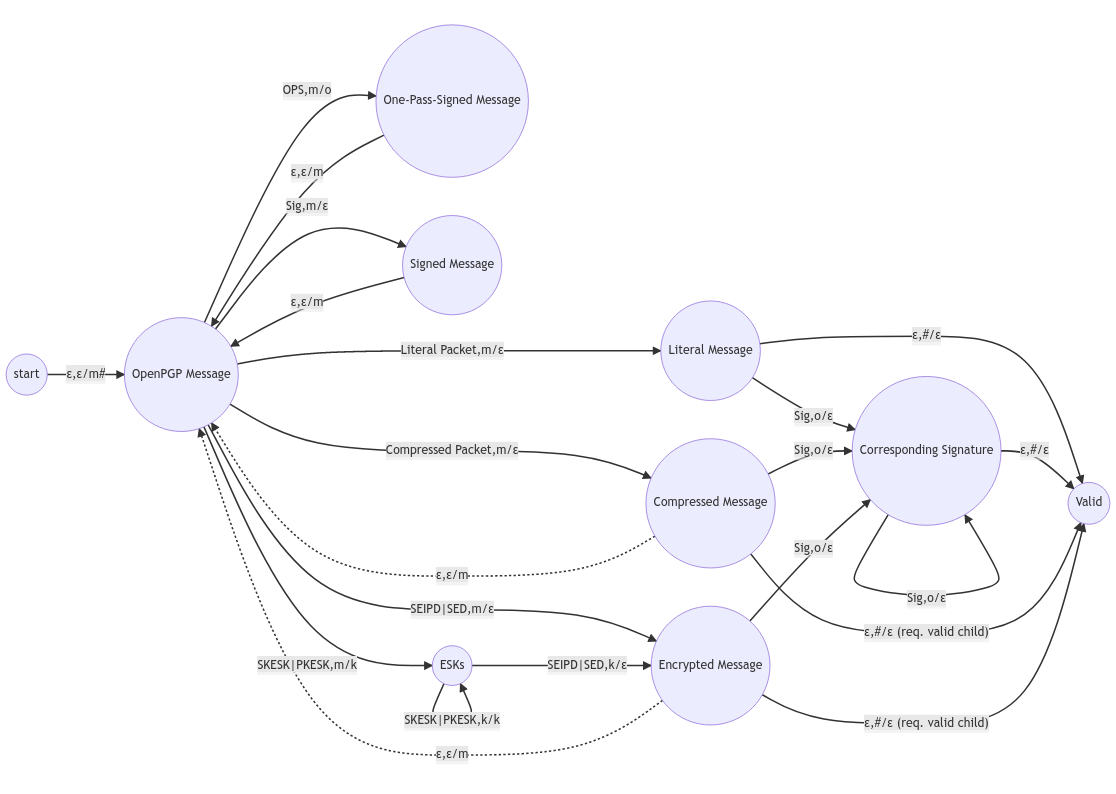
Let’s say we want to validate an OpenPGP message of the format OPS, Literal Packet(_), Sig.
We start with the “start” state to the left. As you can see, the only rule we can apply now is labelled ε,ε/m#, which means we do not read any input and do not pop the stack, but we push ‘#’ and ‘m’ onto the stack. After we applied the rule, we are in the state labelled “OpenPGP Message” and the top of our stack contains the symbol ‘m’.
To advance from here, we can peek at our stack and at the input to check our options. Since our message begins with a One-Pass-Signature (OPS), the only rule we can now apply is OPS,m/o, which requires that the top stack symbol is ‘m’. We read “OPS”, pop ‘m’ from the stack, push ‘o’ onto it and transition into the state “One-Pass-Signed Message”. From here there is only one rule ε,ε/m, which means we simply push ‘m’ onto the stack without popping an item and without reading input. That leaves us back in the state “OpenPGP Message”. Our stack now contains (top to bottom) ‘mo#’.
Now we read the next input symbol “Literal Packet” and apply the rule Literal Packet,m/ε, which means we pop ‘m’ from the stack and transition into state “Literal Message”. The stack now contains ‘o#’.
Next, we read “Sig” from the input, pop ‘o’ from the stack without pushing back an item, transitioning to state “Corresponding Signature”.
Last but not least, we apply rule ε,#/ε, do not read from the input, but pop the top symbol ‘#’ from the stack, transitioning to state “Valid”.
In the end, our stack is empty, we read all of the input data and ended up in an accepting state; The packet sequence “OPS, Literal Packet, Sig” forms a valid OpenPGP message.
Would we start over, but with an invalid input like “Literal Packet, Sig”, the play would go like this:
First, we transition from “start” to “OpenPGP Message” by pushing ‘#’ and ‘m’ to the stack. Then we apply rule Literal Packet,m/ε, read “Literal Packet” from the input, pop ‘m’ from the stack without pushing anything back onto it. This brings us into state “Literal Message” with ‘#’ being our new stack symbol. From here, we only have two rules that we could apply: Sig,o/ε would require us to read “Sig” from the input and have ‘o’ on the top of our stack. Both of these requirements we cannot fulfill. The other option ε,#/ε requires us to pop ‘#’ from the stack without reading input. It even brings us into a state called “Valid”! Okay, let’s do that then!
So far we have read “Literal Packet” from the packet stream. Would the data stream end here, we would have a valid OpenPGP message. Unfortunately, there is still some input left. However, there are no valid rules which allow us to transition any further with input “Sig”. Therefore, the input “Literal Packet, Sig” is not a valid OpenPGP message.
You can try any of the invalid messages listed above and you will see that you will always end up in a situation where you either have not fully read all the input symbols, your stack is not empty, or you end up in a non-accepting state.
You might notice some transitions are drawn using dashed lines. Those illustrate transitions for validating the content of nested packets. For example the Compressed Packet MUST contain another valid OpenPGP message. Depending on how you implement the PDA in software, you can either replace the input stream and use the nested transitions which require you to jump back from a nested “Valid” to the state where the nested transition originated from, or use child PDAs as described below.
The packet sequence Compressed Packet(Literal Packet(_)) for example would be resolved like follows:
From “start” we transition to “OpenPGP Message” by pushing ‘#’ and ‘m’ on the stack. The we read “Compressed Packet from input, pop ‘m’ from the stack and transition to state “Compressed Message”. Since the “Literal Packet” is part of the Compressed Packet”s contents, we now create a new child PDA with input stream “Literal Packet”. After initializing this PDA by pushing ‘#’ and ‘m’ to the stack, we then transition from “OpenPGP Message” to “Literal Message” by reading “Literal Packet” and popping ‘m’, after which we transition to “Valid” by popping ‘#’. Now this PDA is ended up in a valid state, so our parent PDA can transition from “Compressed Message” by reading nothing from the input (remember, the “Compressed Packet” was the only packet in this PDAs stream), popping ‘#’, leaving us with an empty stack and empty input in the valid state.
In PGPainless’ code I am planning to implement OpenPGP message validation by using InputStreams with individual PDAs. If a packet contains nested data (such as the Compressed or Encrypted Packet), a new InputStream will be opened on the decompressed/decrypted data. This new InputStream will in turn have a its own PDA to ensure that the content of the packet forms a valid OpenPGP message on its own. The parent stream on the other hand must check, whether the PDA of it’s child stream ended up in a valid state before accepting its own packet stream.
Initial tests already show promising results, so stay tuned for another blog post where I might go into more details on the implementation 🙂
I really enjoyed this journey into the realm of theoretical computer science. It was a welcome change to my normal day-to-day programming.
Happy Hacking!
4 responses to “Using Pushdown Automata to verify Packet Sequences”
@vanitasvitae complicated as f
Remote Reply
Original Comment URL
Your Profile
This was a nice flashback to my theoretical comp. sci. lectures. I always liked drawing automata, there’s something quite satisfying in translating a grammar into a diagram and making sure both are equal.
Good write-up, Paul!
[…] utilisateur pour les vues MUC et Contact, et des mises à jour SASL.Paul Schaub a écrit un article de blog axé sur les détails techniques de la vérification de la validité des séquences de paquets […]
[…] Schaub a écrit un article de blog axé sur les détails techniques de la vérification de la validité des séquences de paquets […]